22日目の記事: 日本初の競技機械学習大会!【第1回 Cpaw AI competition】開催レポート
24日目の記事: (追記予定)
こんにちわ。 hasegaw こと、さくらインターネット 高火力コンピューティングの長谷川です。
今回は、22日の記事にて紹介された第1回Cpaw AI Conpetitionについて、続きってわけでもないのですが、続編をお届けします。同コンペティションを開催したCpawの伊東さんは高火力コンピューティングにチームでアルバイトしてくれていまして、ある日のこと。
「AIコンペティションを開催したくて、場所を探しています」
「え?ウチ使えるよ」
ということで、さくらインターネットの西新宿セミナールームで開催することになりました。当日は台風が接近していたこともあり、参加者が少なくなってしまうのではないかと心配したのですが、悪天候のなか歩留まり6割というのは最近の機械学習系のイベントとしては良い意味で裏切られた気持ちでした。

先の記事のとおり、 Cpaw AI Competition では、さくらのクラウド 12コア・96GBメモリのインスタンス(Ubuntu 16.04)を用いて、与えられたデータセットに対する分類器を生成、分類結果を Web サイトから提出します。提出したスコアはそのまま 1% == 1ポイントとして加算されます。つまり65.2% の分類器をつくれば 65 ポイント獲得できるわけですね。
競技時間は 13:30-18:00 のおよそ 4.5 時間。さくらインターネットの社員(わたし含めて2名)は会場運営支援で現地にいたのですが、 4 時間ボケっとしているのは、ちょっと暇です。と、いうわけで。
「伊東くん、私にも問題解かせてよ」
とお願いして、他の参加者と同じように問題を解いてみることにしました。下記は、実際に問題を解いた手順を再現したものですが、当時書いたコードは既に失ってしまったので、書き直した「再現コード」で解説します。
■ 芸能人ブログ記事の分類問題→絶望
最初に手を出したのは芸能人ブログの分類問題(entertainer_blog)です。データセットは Cpaw オリジナルのもので(本稿執筆のために Cpaw から提供を受けていますが)、 Cpaw の皆さんがあらかじめスクレイプ、1記事1テキストファイルに変換されたものです。ブログエントリの教師データを用いて分類器を訓練し、クラスラベルが与えられていないブログエントリを分類することが目標です。
entertainer_blog/train/
entertainer_blog/train/mamoru_miyano
entertainer_blog/train/mamoru_miyano/10.txt
entertainer_blog/train/mamoru_miyano/1000.txt
entertainer_blog/train/mamoru_miyano/1005.txt
entertainer_blog/train/mamoru_miyano/1021.txt
entertainer_blog/train/sano_hinako
entertainer_blog/train/sano_hinako/1004.txt
entertainer_blog/train/sano_hinako/1008.txt
entertainer_blog/train/sano_hinako/1012.txt
entertainer_blog/train/sano_hinako/1014.txt
entertainer_blog/train/shinozaki_ai
entertainer_blog/train/shinozaki_ai/1003.txt
entertainer_blog/train/shinozaki_ai/1006.txt
entertainer_blog/train/shinozaki_ai/1010.txt
entertainer_blog/train/shinozaki_ai/1018.txt
entertainer_blog/train/shinozaki_ai/102.txt
....
データファイルの内容の例

訓練用データセットは下記のとおりの構成でした。
訓練用データ(ラベルあり)
461 shinozaki_ai
509 uesaka_sumire
397 mamoru_miyano
210 sano_hinako
合計 1577
テスト用データ(ラベルなし;スコア獲得用)
合計 1972
データセットを数ファイル覗いてみると、これらの芸能人が誰なのか正直全然わからないですけども、クラスによっては特定の締め方があったり、顔文字の傾向があったり、ということがわかりました。今回は、このデータセットを手軽に処理する目的で Jubatus を用いることにしました。 Jubatus の場合 ngram を用いた特徴量への変換などが標準で備わっていますので、今回のようなデータセットなら、簡単に「とりあえず」食わせられるからです。
wget http://download.jubat.us/apt/ubuntu/xenial/binary/pool/jubatus_1.0.6-1_amd64.deb
apt install ./jubatus_1.0.6-1_amd64.deb
pip3 install --user jubatus
今回は分類問題なので Jubatus のなかでも jubaclassifier を使用します。以下のようなファイルを作成します。 n=6 にしましたが、ここには強い理由はありません(とりあえずノリで決めました)。既存のサンプルを参考に、設定ファイルに指定して jubaclassifier を起動します。
jubaclassifier はポート 9199 で待ち受けており、 Python で記述する学習&予測プログラムから利用します。
jubaclassifier --configpath jubaclassifier.json
そして訓練用データセットがクラスラベルごとにディレクトリで分けられていること、データセットサイズに対してインスタンスのメモリ容量が十分なことから、下記関数でデータセットを読み込むことにしました。
次のコードが Jubatus を用いてデータセットを分類し、Cpaw AI Competition での提出用CSVフォーマットで stdout に出力するソースコードです。
ここまで準備ができたら、実際にデータセットをロードして、 jubaclassifier を用いてオンライン学習し、テストデータを分類します。ここで、標準出力に表示される結果の例を示します。
0.txt,uesaka_sumire
1.txt,shinozaki_ai
2.txt,uesaka_sumire
3.txt,uesaka_sumire
4.txt,mamoru_miyano
5.txt,mamoru_miyano
6.txt,shinozaki_ai
7.txt,shinozaki_ai
8.txt,uesaka_sumire
9.txt,shinozaki_ai
このデータをコンペティションの採点システムに提出すると、得られていた精度はなんと 30% 以下!!4クラス分類だと完全ランダムでも25%前後になるはずですから、いっそのこと全部 shinozaki_ai ラベルで提出した場合のスコアと大差がない。まったく駄目!!
正直、高火力コンピューティングをお客様に紹介して回ったり、プレゼンして回ったりする立場の私がコレなのは本当に恥ずかしてお客様などに顔向けできないなぁ、と思い、動揺し、死にたくなりました。いっそのこと Cpaw に貸してあげた採点サーバーに root で乗り込んでいって DROP DATABASE クエリを叩き込んでしまいたいという気持ちになりましたが、個人的な感情でそんなことをするわけにもいきません。実は、当日は ngram の n=2 で精度が得られなかったため順番に増やしていって 6 まで上げたのですが、これだけで、精度はあがりません。
一旦あきらめて、とりあえず他のデータセットに取り組むことにします。
■ 泣きそうになりながら、マルウェアURLの分類問題
次に取り組んだのは、マルウェアURLの分類問題です。下記URLで取得できる、URLデータセットが先と同じように1サンプル1テキストファイルとして用意されており、オリジナルデータからラベルが取り除かれたテストデータが正常なURLか、グレイゾーンなURLかを判断することが目標です。
Malware URL
http://malwareurls.joxeankoret.com/
データセットのディレクトリ/ファイル構造
train/normal/
train/normal//1007.txt
train/normal//101.txt
train/normal//1011.txt
train/normal//1013.txt
train/malicious/
train/malicious//0.txt
train/malicious//1.txt
train/malicious//10.txt
train/malicious//100.txt
...
あるデータファイルの中身の例

テキストファイルの中が芸能人のブログ記事からURLにかわり、ラベルが変わっただけで、基本的にデータフォーマットは一緒です。
というわけで、遠慮なく先程の dataset.py と classifier.py に突っ込んでみます。 URL は基本的にアルファベットや数字の集合で、N の値はそこそこ大きい必要があるでしょう。なので N はとりあえず、引き続き 6 ぐらいにしておきます。
先程起動した jubaclassifier は芸能人ブログの学習データを持っているので、ここでいったん同プロセスを再起動しておきます(もっといい方法があるのでしょうか?使い慣れているわけではないので、よくわかっていません)。malware_urls.py を実行した結果がこちら。
採点サーバに送ると、またもや精度は 60% にも及びません(2クラス分類なので全く駄目な結果ということです)。もうだめだー!!!逃げたい!!!
そう思っていたところで、 Cpaw 運営側から採点システムの不具合があり、正確な採点がされていないので,データを再提出するようにという指示。先の芸能人ブログ分類、マルウェアURL分類の結果を再提出した結果、こんな感じになりました。
entertainer_blog: 精度 94.6%
malware_urls: 精度 83.7%
なんだぁ〜〜〜〜。ちゃんと分類できてるんじゃん!本当に焦って泣きそうでしたよ!!よかった。
■ 調子に乗りながら、マルウェア分析の分類問題
次はマルウェア分析問題にとりかかっていきます。このデータセットは下記サイトから入手できる MalwareTrainingSets が先と同様のフォーマット(ただしJSON)に変換されているものです。
Free Malware Training Datasets for Machine Learning
https://github.com/marcoramilli/MalwareTrainingSets
データセットのディレクトリ/ファイル構造
train/APT1/1046.json
train/APT1/1051.json
train/APT1/1063.json
train/APT1/1065.json
train/Crypto/0.json
train/Crypto/100.json
train/Crypto/1000.json
train/Crypto/1002.json
train/Locker/1004.json
train/Locker/1012.json
train/Locker/1037.json
train/Locker/1048.json
train/Zeus/1.json
train/Zeus/10.json
train/Zeus/1001.json
train/Zeus/1005.json
...
あるデータファイルの中身の例

Cpawからデータセットのフォーマットが事実上先程と同じなので、遠慮なく分類器にかけていきます。もしかすると、当日では、JSONを解析して特定の値のみを評価したかもしれません(よく憶えていません)。
得られた結果は以下のとおり。
malware_analysis: 精度 99.6%
さてここまで entertainer_blog 94.6%, malware_urls 83.7%, malware_analysis 99.6% の精度が出せたので、私のスコアは 94+83+99 で合計 276 となり、二番手グループに大躍進です!! (会場スポンサーですけど)
■ ニューラルネットワークで"ファッションMNI?T"
さてさて!
気分がよくなってきたところで、次のデータセットに取り組んでいきましょう。ここまではテキストのデータセットばかりを選んできましたが、残っているデータセットは「ファッションMNI?T」と「古代文字」のふたつ。どちらかを先に試すか?と思ったら、まずは前者かな、と思いました。 MNIST といえば 28x28 の 10 クラス分類問題で、名前から想像するに同じような要領でいけるのではないか、と思い、データセットを覗いてみることに。

これもボーナス問題ですね!オリジナルの Fashion MNIST データセットでは黒塗りマスクがないのですが、今回のは黒塗りマスクのイタズラがされているデータでした。
これはイケる、という確信を得ます。MNIST同様、28x28のモノクロサイズの10クラス分類。データセットをひと目みるとわかりますが、全ての画像に同一パターンの黒塗りがかかっています。畳み込みニューラルネットワークを使用するとこの黒塗りエッジ部分などが邪魔をするかもしれませんが、このデータを単純に線形結合で入力する場合は、オリジナルのファッション MNIST を 14x14 にリサイズされた状態である、と解釈できるのではないでしょうか。もう、これは 14x14 の MNIST にしか、私には見えません。
この問題をどう解くか、ですが Cpaw AI Competition のレギュレーションでは、イベントで提供された 12コア96GB を使いまくっていいので(畳み込んでいるとあっという間に時間が過ぎてしまいそうですが)線形結合で殴るぐらいの計算リソースと残り時間はあります。また、畳み込むと上にかぶっているマスクが邪魔になるだろうでしょうから、結果が予測できません。なので、線形結合モデルでいくことにします。
とりあえず、Chainerフレームワークをインストールします。
pip3 install chainer
データセットはこれまで通り各クラスがディレクトリで分けられて提供されていましたが、テキストファイルではなく画像なので、データセット読み込みを実装します。普段は cv2.imread() のほうが使い慣れているのですが、cv2モジュールがすぐインポートできなかったので、今回はPILを使ってみました。
以下が Chainer を使ってニューラルネットワークを訓練し、テストデータを予測するためのコードの例です。
このコードを実行し、得られた結果を採点サーバに送信したところ 81% の精度が得られ、私は大会で暫定首位に躍り出ました。(会場スポンサーですけど)
■ これは引っ掛けデータセットな「古代文字」
さて、残りは古代文字データセットです。このデータセットは下記URLから入手できる古代文字画像が、一文字ごと、画像ファイルに分割された状態で提供されました。
文学オープンデータ共同利用センター / Center for Open Data in the Humanities
http://codh.rois.ac.jp/

正直、このデータセットはちらっと見るだけでも 13:30-18:00 のコンペティションの中で扱うデータセットとしては非常に重いです。ファッションMNISTのようにある程度の正規化がされているわけでもなく、さすがに畳み込みニューラルネットワークなどのアプローチで、きちんと回さないと、精度が出ないのではないか?という気がします。
とはいえ、この段階で残り1時間ほど。チャレンジできるところまでチャレンジしましょう。(会場スポンサーですけど)
■ 突然のカーテンコール
……と思ったところで、運営からその時点の暫定順位の発表があり、運営の伊東さんから下記の案内がありました。
「あ、ちなみにこの hasegaw って人は会場スタッフなので表彰対象外です」
というわけで、私の AI Competition は散って終わったのでした。表彰対象外とは….— Takeshi HASEGAWA (@hasegaw) October 29, 2017
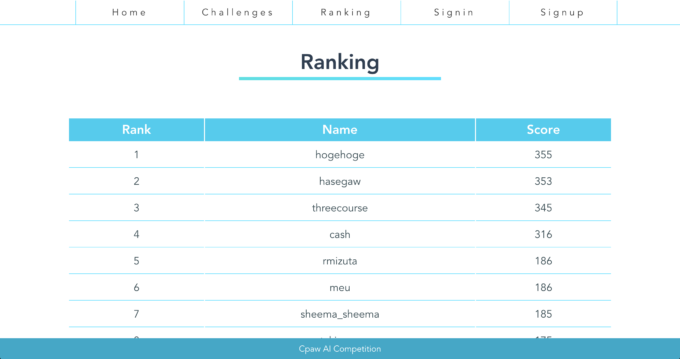
なお、今回のブログ記事執筆のために作成しなおしたコードでは、下記のスコアが得られました。
entertainer_blog: 精度 94.6%
malware_urls: 精度 83.7%
malware_analysis: 精度 99.6%
fashion_mnist: 精度 81.9%
小数点以下切り捨ての合計スコアは357ですので、当日このスコアが出せていたら、トップに踊りでて Google Home mini を勝ち取っていたかもしれません。😭

後日自分で購入した Google Home mini
もちろん、今回はたまたまデータセットと私のとった手段がうまくはまってスコアが伸びただけしかありません。会場には、スコアを伸ばすことを重きにおくのではなく、フルスクラッチで機械学習アルゴリズムを実装するところからスコアを積み上げていた方もいらっしゃるようで、本当に頭がさがります。
次の機会には、もし会場スポンサーの立場であっても、きちんと参加登録してコンペティションに臨んでみたいと思います。
■ 終わりに
機械学習って、聞いたことがあるけど未だ試していなかったり、もしくはちょっと勉強してみたという方も増えてきているのではないでしょうか。
私も、もともと「機械学習やディープラーニングってすごいなぁ」と思いながら、 IkaLog というスプラトゥーンの画像認識ソフトを作っていく過程で、意図せず、各種機械学習アルゴリズムのパワーを体感して、そこから Coursera の Machine Learning コースを受講した程度の知識しかありません。1年ほどスプラトゥーンの画像データに取り組んだ経験がある以外は、機械学習について凡人レベル、もしくはそこに毛が生えた程度の知識しかありません。
しかし機械学習は、ちょっとモチベーションがあると、その状況なりの使い道や楽しみ方が見つかります。また、今回のような問題で7割8割の精度が出せれば、業務上でも自分の仕事の手間を削減したり、ちょっとした業務効率化で効いたりするものです。さくらインターネットでも、機械学習未経験のデータセンター現地スタッフが独学で Jubatus を用いたオペレーション業務の効率化にも取り組んだりもしています。
Cpaw では、今後とも同様のオンラインイベントやオフラインイベントを開催すると伺っています。機会があれば、このようなイベントにぜひとも参加してみてください。
■ おまけ
過去に参加したアドベントカレンダー
- 2015年12月: スプラソン機材セットをつくりました
- 2015年12月: おうちハックで戦った話
- 2015年12月: Fluent-bit と XBee で作るセンサーネットワーク
- 2013年12月: 次世代I/Oインターフェイス「Eject-io」
- 2012年12月: 割り込みはいかにしてゲストの割り込みハンドラに届くのか
- 2011年1月: FreeBSD VIMAGEを使ったTCP/IPのルーティング デモンストレーション
0 件のコメント:
コメントを投稿